

Unleashing Autonomy: The RSS Agent 1
Loading and processing RSS feeds

In this series of articles we are going to be building an RSS Agent to grab and read blog posts. This is part of our whole information gathering process which will be used everyday as part of our overall Ideas Agent.
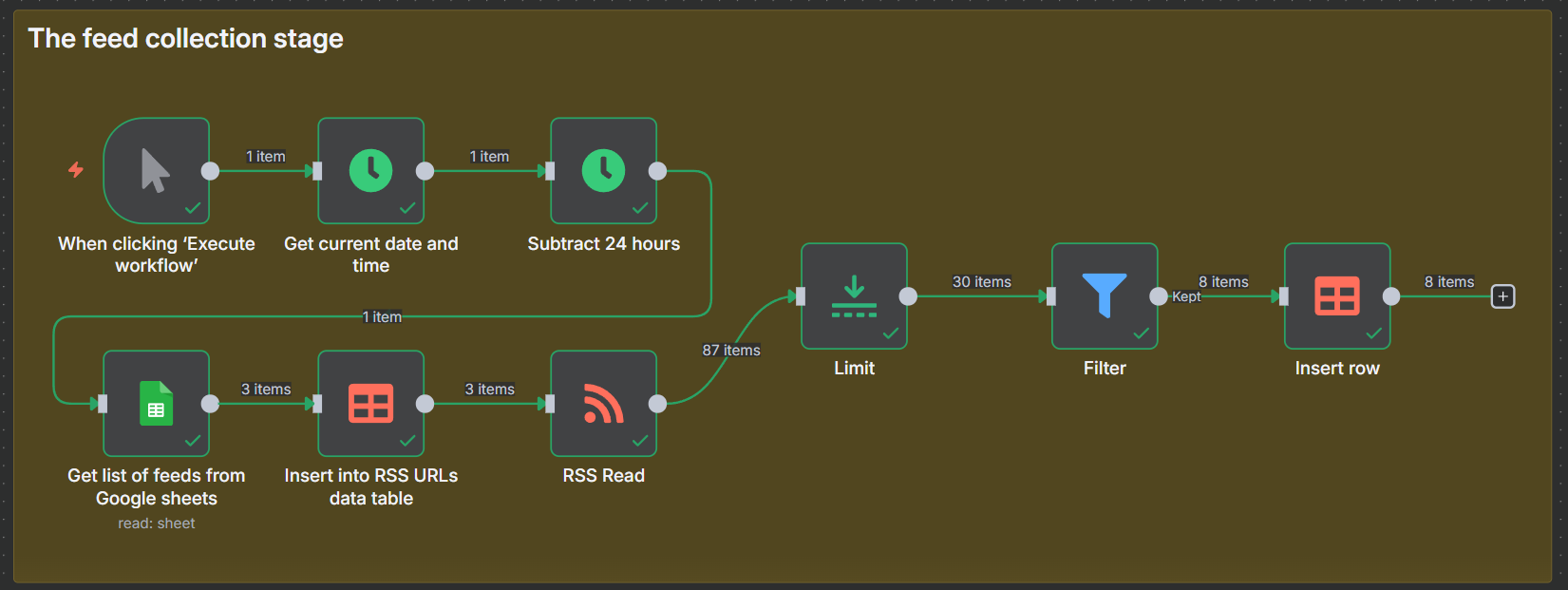
There are two routes we can go down here, one is free, the other uses a paid service. In this article I am going to be showing you the free route, because, hey, free is good. There are a few advantages to using the paid route (and I will cover these later), but these are not needed for this (if ever), and this is a good exercise to show you how powerful n8n can be.
Let’s get started.
First, for testing, we are using a manual trigger. Then we get to these two nodes.
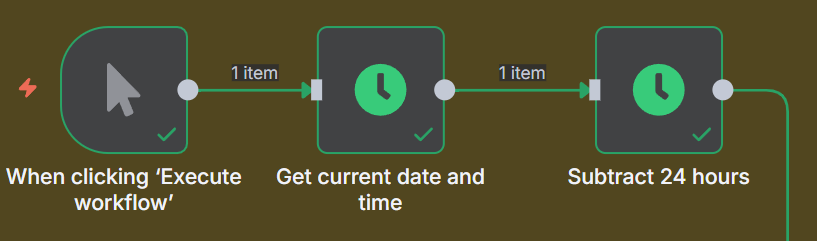
We are using the Date/Time node to get the current Date and Time, and we will save that in a variable currentDate.
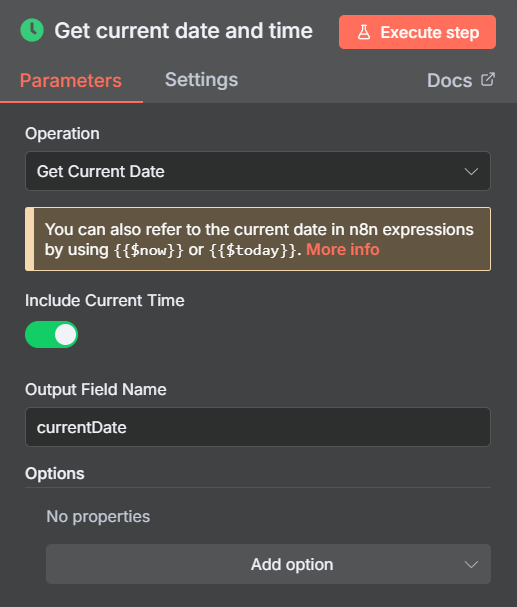
Then, we need another Date Time node to work out what date is was 24 hours ago. We are using the currentDate we save in the previous node as the input.
We are doing this so we can have a variable previousData available later in our workflow to filter the feeds we retrieve so that we only get new stories from the last 24 hours.
Next, we have this…
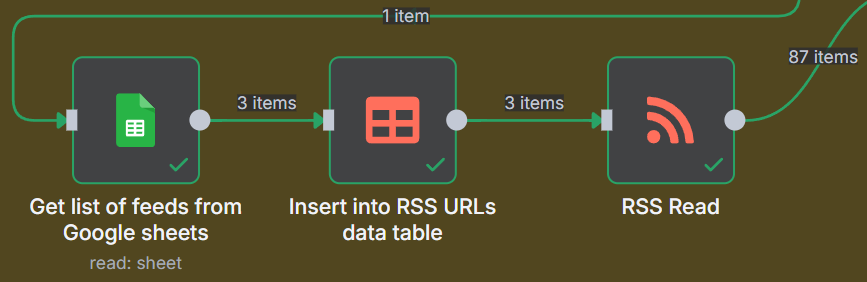
Here we are reading a list of feed URLs we have created in a Google Sheet.
You will need to create a new Google Sheet, I am calling mine RSS Feeds, in here you will need to put in a couple of links to RSS feeds of blogs that cover your niche or niches.
You will need a header row too, here is a quick example.

Here is the Google Sheets node setup.
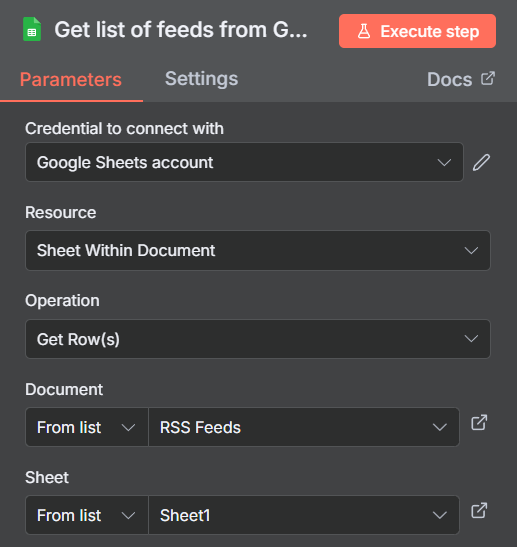
Next we need to store them in a Data Table. Data Tables are simple databases that were introduced into n8n a few months back. Previous to that you had to setup a Postgres database alongside your n8n instance to store information, but now, this process is simple.
You will need to create a n8n Data Table, You can do this in the main dashboard.

If you do not have the data tables option there, then this means your n8n installation is not up to date. If you have installed with Docker Desktop or DockPloy this is because it is pulling in the latest ‘stable’ release and it doesn’t have the latest features.
As soon as I have finished writing this article I will write a quick guide on updating to the latest version with Data Table support.
I have created a Data Table with one column called rssFeed, the other three columns id, createdAt, and updatedAt are created automatically.

So, we are going to take the output from the Google Sheets node and feed it into the data table like this:
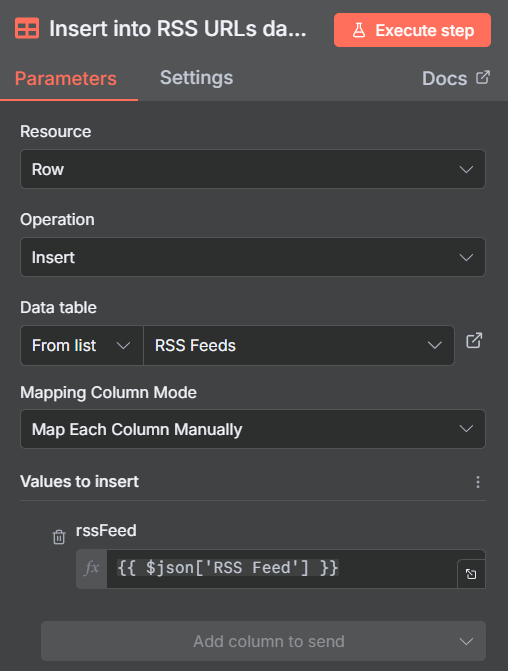
Then we are going to add in a RSS Feed node and pass in the RSS Feed data table, which contains a list of URLs. Remember, you are choosing this from the left hand pane.
The RSS Feed will automatically loop through all of the feed addresses in the Data Table and go and fetch the full feeds from the websites.
We will now have a big list of articles and summaries to pass on to the next block.
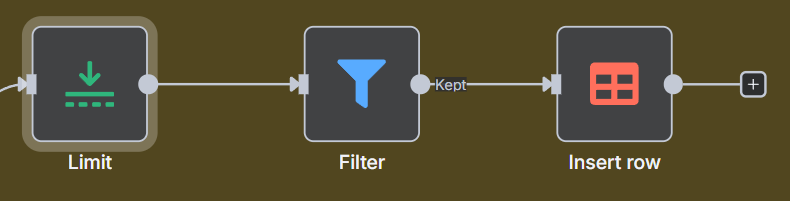
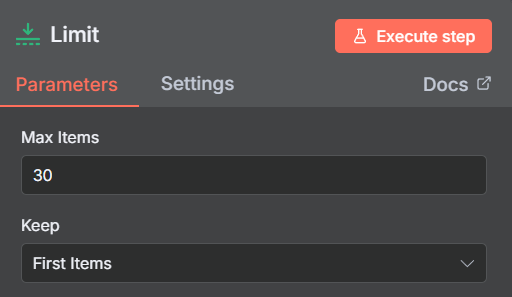
Next we are going to add a Limit node to reduce the amount we are going to process, this will be a trial and error step as some sites return hundreds of articles, some sites only ten.
Then we are going to filter out any articles older than 24 hours using our previousDate variable we set at the beginning of the workflow. To do this add a Filter node.
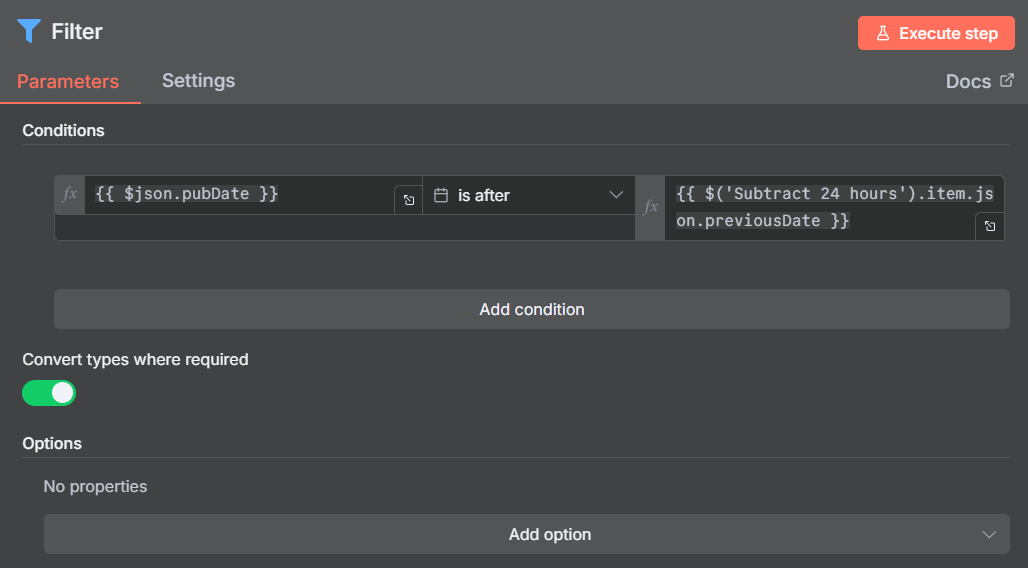
Make sure Convert types is turned on.
Now you can filter first, and then limit the data, just swap the blocks around if you want to. Just run a few tests to see what results you are getting with your feeds.
No for the final part of the process, and that is to store the feed in another data table which only contains articles written in the last 24 hours.
So let’s be clever here, we are going to use this data with an AI, so why not ask the AI what data it would prefer. I pasted in a copy of the feed and here is what it gave me…
Key Feed Structure
Each article entry contains these essential fields for article selection:
title: Article headlinecreator/dc:creator: Author namepubDate/isoDate: Publication timestamplink: Full article URLcategories: Topic tags (e.g., “Right to Repair”, “Windows 10”, “News”)content/contentSnippet: Brief summary/description (150-200 characters)content:encodedSnippet: Longer plain text excerpt (1000-2000+ characters) of the full article
Recommended Fields to Pass to an LLM
For article selection and investigation, you should pass:
title- Quick understanding of topiccreator- Author identificationpubDateorisoDate- Recency/timelinesscategories- Topic classificationcontentSnippet- Very brief summarycontent:encodedSnippet- Detailed preview without HTMLlink- Reference URL
Optional fields:
guid- Unique identifier if tracking articles
What to Exclude
content:encoded- Full HTML markup version (too verbose, contains formatting)Duplicate fields - The feed has both
content/contentSnippetanddc:creator/creatorwhich are identical
There you go, everything we need to move on (this is how you should be using AI to help you).
We don’t really need categories so I will nix it. Also makes the data easier as it may not be included. (less errors to think about).
I created a Data Table and added the following columns:

title, creator,pubDate,contentSnippet,contentEncodedSnippet,link
Now for the final part
I added the Data Feed node in and configured it like this:
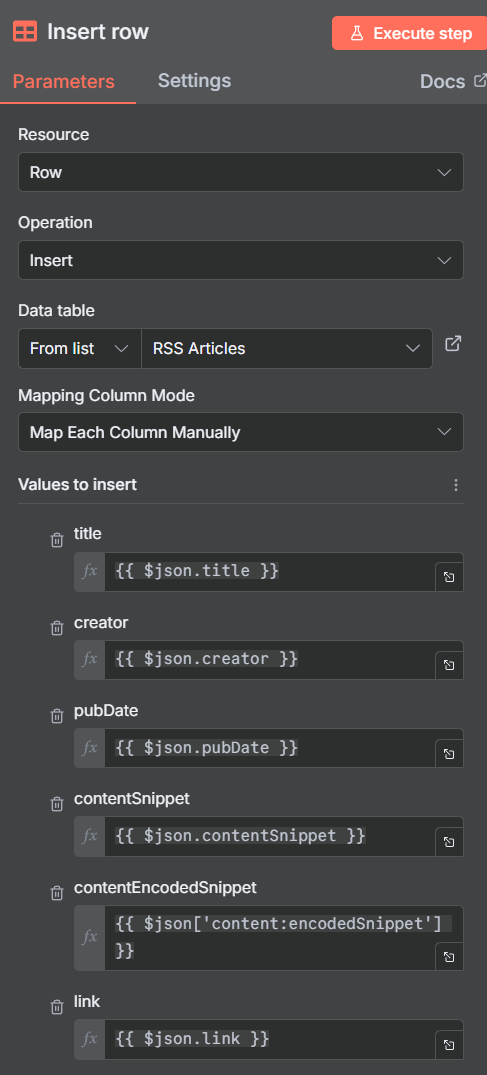
Now we have a Data Table filled with the information we need to be processed by the next step of the workflow.
In the next article we will cover setting up an AI to read and understand the feed, and the we will talk about cleaning up the tables as part of a daily schedule so we can start fresh everyday.
Any questions, please ask in the comments.
ok, made it through... question time. My content:encodedSnippet does not make it through the FILTER. Any thoughts on why? Filters isoDate and above.